February 13, 2023
February 13, 2023 Rishi Airy
Rishi Airy![]() Evaluate your current IT inventory.
Evaluate your current IT inventory.
![]() Discover and plan.
Discover and plan.
![]() Build.
Build.
![]() Run.
Run.
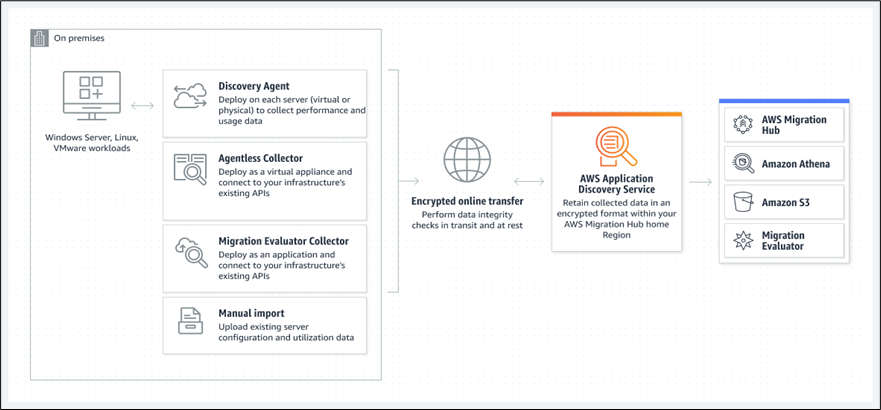
To get started, you simply install the small, lightweight agent on your source hosts. The agent unobtrusively collects the following system information:
 Installed applications and packages.
Installed applications and packages.- Running applications and processes.
- TCP v4 and v6 connections.
- Kernel brand and version.
- Kernel configuration.
- Kernel modules.
- CPU and memory usage.
- Process creation and termination events.
- Disk and network events.
- TCP and UDP listening ports and the associated processes.
- NIC information.
- Use of DNS, DHCP, and Active Directory.
The agent can be run either offline or online. When run offline, it collects the information listed above and stores it locally so that you can review it. When run online, it uploads the information to the Application Discovery Service across a secure connection on port 443. The information is processed and correlated, then stored in a repository for access via a new set of CLI commands and API functions. The repository stores all of the discovered, correlated information in a secure form.
The agent can be run on Ubuntu 14, Red Hat 6-7, CentOS 6-7, and Windows (Server 2008 R2, Server 2012, Server 2012 R2). We plan to add additional options over time so be sure to let us know what you need.
The Application Discovery Service includes a CLI that you can use to query the information collected by the agents. Here’s a sample:
- Describe-agents – List the set of running agents.
- Start-data-collection – Initiate the data collection process.
- List-servers – List the set of discovered hosts.
- List-connections – List the network connections made by a discovered host. This command (and several others that I did not list) gives you the power to identify and map out application dependencies.
About the Author:

IT Leader/Cloud architect with 18+ years of global consulting experience (USA, Mexico, Japan, India and south east Asia) in areas of leadership in IT Deliveries, strategy, Project Management, Vendor Management and business/ IT transformation service, and Cloud consultancy.